かんたん・セキュアにデータ連携…
#4 データ連携(iPaaS)基盤からデータ活用基盤へ進化。新機能「データベース」の活用法

執筆・監修者ページ/掲載記事:11件
かんたん・セキュアにデータ連携(iPaaS)を実現できる「IIJクラウドデータプラットフォームサービス」は、使い方が無限大。本企画では、具体的にどんな活用方法があるのか、開発者に実践を交えて解説してもらいます。今回のテーマは「データベースの活用」です。
※データベース機能は2023年8月にリリースしました。

- 目次
関連資料

登場人物

IIJ
クラウド本部
プラットフォームサービス部長
鈴木 透

IIJ
クラウド本部
プラットフォームサービス部 プラットフォームサービス課
佐藤 陽平
新機能「マネージド型データベース」をリリース
前回までで、「IIJクラウドデータプラットフォームサービス」を使えば、簡単にSaaSやオンプレミスとデータ連携できることが分かりました。データ連携が進んでいくと、単なるデータの受け渡しだけではなく、データを一時的に蓄積したり集計したりする機会も増えてきそうですよね。連携するデータを1ヵ所に集めて一元的に管理できると楽になりそうですが…
鈴木
連携アダプターを使えば、Oracle DatabaseやMicrosoft SQL Serverなどのデータベースとつなぐことができますが、データベースの形式に加工する作業も結構手間なんですよね。加工のためのデータの一時的な置き場所も必要になってきます。
もしかして、そういう作業も「IIJクラウドデータプラットフォームサービス」上でできるんですか?

鈴木
実はそうなんです。2023年8月にリリースしたデータベース機能を使えば、データの蓄積や加工、集計も「IIJクラウドデータプラットフォームサービス」上で行えますよ。
どんどん便利なサービスになっていきますね!
佐藤
リリースするのは、PostgreSQLをベースにしたマネージド型のデータベースです。データベースのバックアップやパッチ適用もIIJ側で対応します。
CPUやメモリのスペックを選べて、必要に応じてストレージ容量を追加することも可能です。PostgreSQLのGUI管理ツールである「pgAdmin」も使えますよ。
図1:pgAdminの操作画面
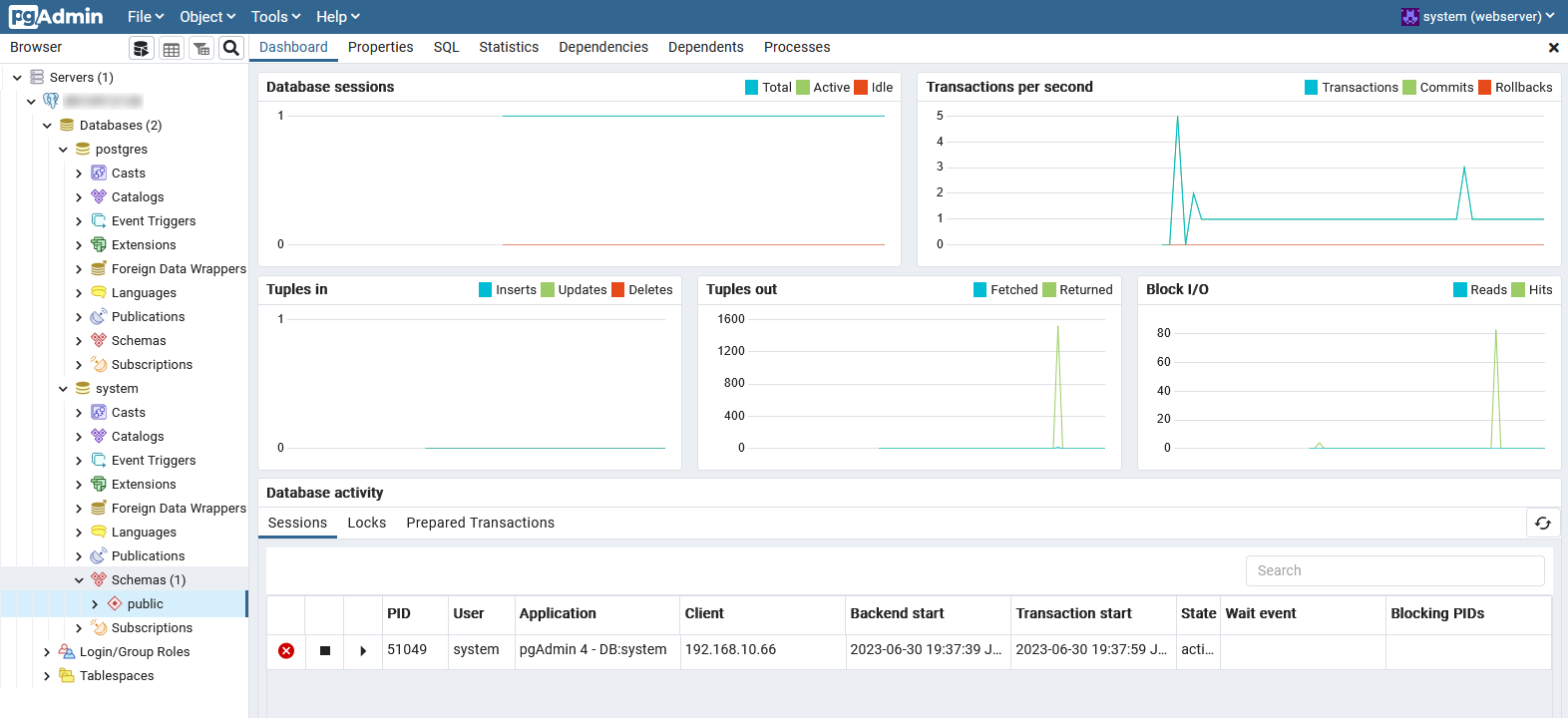
(クリックすると拡大します)
SaaSデータのコピーDB、前処理を行う中間DBなど使い方は多彩
どんな使い方ができるんですか?
鈴木
例えば、SaaSデータのコピーDBとして利用できます。SaaSから定期的にデータを取得し、コピーをデータベースの形式で保持しておけます。SaaSのAPIにアクセスせずとも、使い慣れたSQLを利用して様々なシステムからSaaSのデータを参照・活用できるのです。SaaSデータのバックアップとしても使えますね。

佐藤
従来は、連携の前処理のためのデータの一時蓄積はCSVなどのファイル形式で保存する必要がありました。今回データベース機能を追加したことで、テーブルをそのままの形式で蓄積することや、SQLによる結合や集計が可能になったため、処理速度や利便性が向上しました。
DBの構築やデータソースとの連携はGUIで簡単に行える
データベース機能も、サービスのGUIから使えるのですか。
鈴木
はい。今回は、kintoneのデータをPostgreSQLで扱えるようにするまでの手順を紹介しますね。先ほどお話した、SaaSデータのコピーDBとしての使い方になります。図2が今回のフローです。kintoneとは既に連携している状態から始めます。連携手順については以前もご紹介しましたね。
図2:今回のフロー
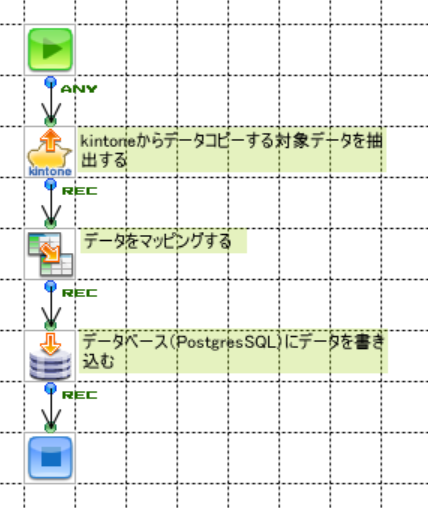
今回取り込むkintoneのデータは図3の通りです。
図3:取り込み元となるkintoneの顧客リストサンプル
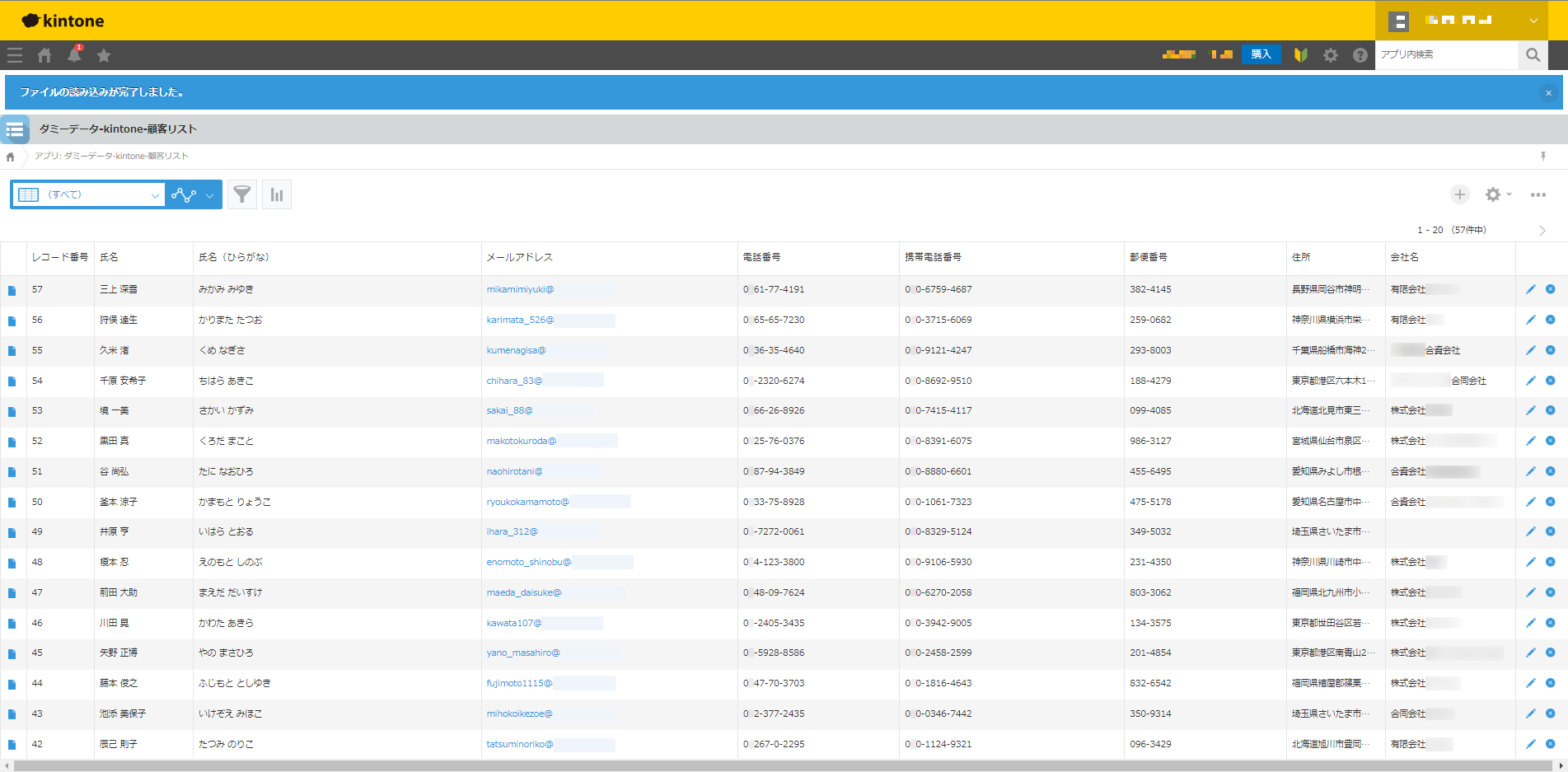
(クリックすると拡大します)
次に、サービスのGUIから「kintoneビルダー」のデータ抽出操作画面を開きます。図4のように、取り込みたいフィールドコードにチェックを付け「保存」をクリックします。
図4:kintoneビルダーでのデータ抽出
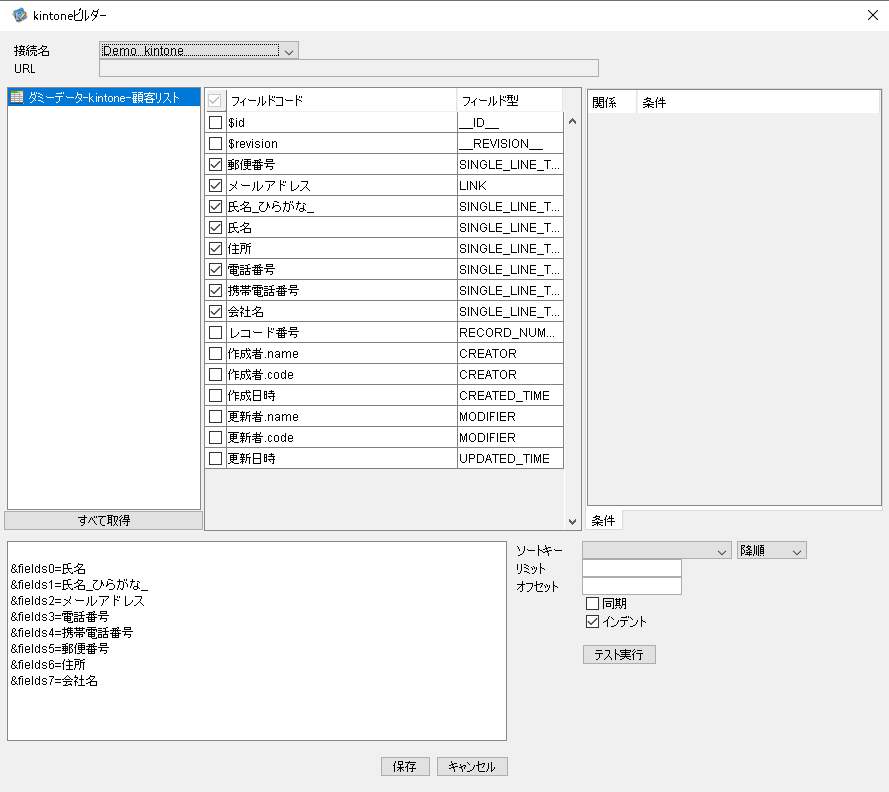
(クリックすると拡大します)
次に、データベースのテーブルを更新する際に使う「RDBPutコンポーネント」を開き、その中の「SQLビルダー」を開きます。
図5:RDBPut内のSQLビルダーの設定
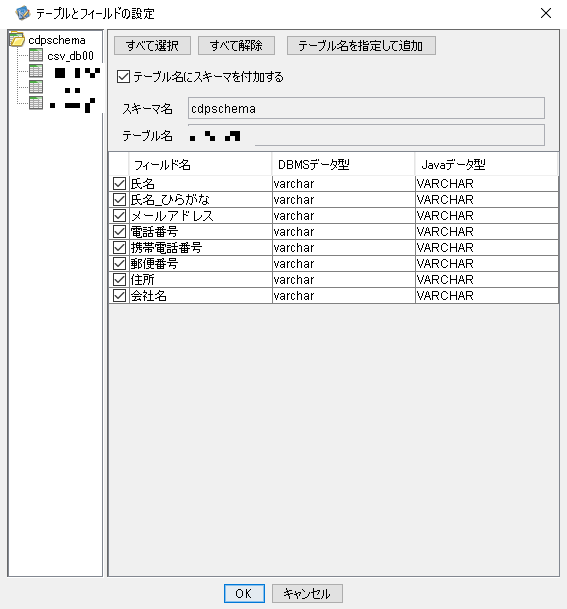
(クリックすると拡大します)
ここでPostgreSQL側にデータを取り込む設定を行います。先ほどkintoneビルダーで選択した、取り込みたいフィールドコードをチェックします。任意のスキーマ名を設定して「OK」をクリックします。これでkintoneデータのPostgreSQLへの取り込みは完了です。
図6がデータベース内の様子です。kintoneのデータが書き込まれていることを確認できますね。
図6:コピーされたDB内の様子

(クリックすると拡大します)
バラバラなマスターデータの集約も可能に
本当ですね。データベースは難しいイメージがありましたが、これなら簡単に使い始められそうです。
佐藤
オンプレミスやクラウド上に新たにデータベースを構築する必要がないのも大きなメリットです。すぐに利用を開始できる上、自前でインフラを構築する場合に比べて、コストも大幅に低減できます。
これまで紹介してもらった以外には、どんな使い方ができますか。
鈴木
複数のマスターデータを集約して統合マスターとして利用することもできますよ。
例えば、小売業では店舗とECサイトで商品マスターや顧客マスターが違ったり、事業ごとに別々にマスターを管理していたりすることがあります。そうすると顧客情報や購買履歴もバラバラ。複数のマスターを突合しないと、いつ・どこで・どんなものを買ったかという情報が正確に把握できません。せっかくデータはあるのに、これでは“宝の持ち腐れ”です。
コード体系が異なる複数のマスターを作り直すのは大変な手間ですが、今回の機能を使えば、変換表による関連付けや統一コードの付与を行うことで、複数のマスターデータを集約できます。
データ連携機能との組み合わせで、更新されたマスターデータをすぐに取り込んだり、情報が更新されたら連携先のマスターに反映したりする。そんなマスターデータ管理も一気通貫で実現できます。uSonarなどのクラウド型名寄せサービスとの連携にも対応しています。
更に前回紹介したプライベートネットワーク接続を活用すれば、非常にセキュアなデータベース活用も可能になります。
データ連携実行中にエラーが発生しても、処理の途中から再開
なるほど。データ活用の幅が大きく広がりますね。
佐藤
もう1つ、特筆すべき特徴があります。それが「チェックポイント機能」です。
チェックポイントとは、実行データを保存するポイントのこと。データ連携フローの実行中にエラーが発生しても、このポイントまでの実行データは保存されているので、チェックポイントから処理を素早く再開することができるのです。一からデータ連携フローをやり直す必要がないため、エラー発生時の障害対策として非常に有効です。
データベース機能を使えば、より高度なデータ処理やデータの付加価値向上も簡単にできますね。
佐藤
これまでの「IIJクラウドデータプラットフォームサービス」はデータ連携のハブという使い方がメインでしたが、データベース機能のリリースにより、包括的なデータ活用プラットフォームへと進化しました。多彩なデータ活用が進み、これまで以上にDXの取り組みが加速するでしょう。
気になることがあればお気軽に
関連資料
