かんたん・セキュアにデータ連携…
データマスキングとは?効果的な活用法からツールの選定ポイントまで徹底解説

執筆・監修者ページ/掲載記事:11件
AIによる要約 β版(Microsoft Copilot)
- データマスキングは、機密情報を保護しつつデータ活用を促進する手法で、DX推進に不可欠です。
- データマスキングと暗号化の違いや、具体的な活用法、選定ポイントを詳しく解説しています。
- IIJのクラウドデータプラットフォームサービスは、データマスキングを容易に実現できる魅力的なソリューションです。
デジタルトランスフォーメーション(DX)を進める上で、データの活用は必須の取り組みです。しかし、企業が扱うデータの中には機密性の高い情報や個人情報なども含まれています。外部流出や不正利用を防ぐため、厳格な管理が必要ですが、そうなるとデータの活用や分析が難しくなります。この課題を解決するのが「データマスキング」です。この手法が求められる背景や仕組み、効果的な活用法、そして製品の選定ポイントまで徹底解説します。
- 目次
データマスキングとは?
データマスキングとは、元データの特定部分を別の数字や文字列に置き換えることです。例えばユースケースの1つとして「データの匿名化」が挙げられます。第三者に開示できない重要情報やプライバシーを保護するため、データを他の文字列などに変更して隠蔽します。
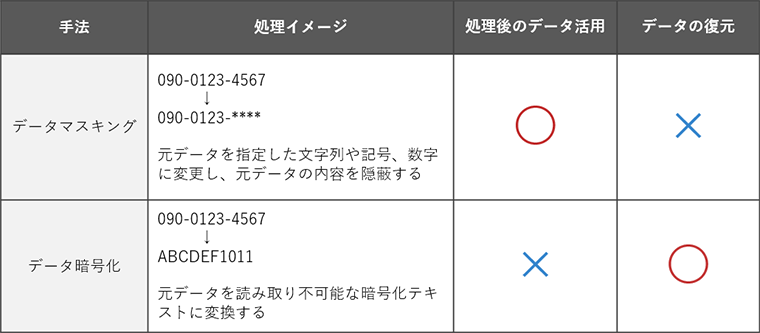
重要な個人情報の1つである電話番号を例に説明しましょう。「090-0123-4567」という電話番号が第三者に見られたら、悪用される恐れがあります。しかし、番号の一部を「*」で隠蔽し「090-0123-****」とすれば、仮に第三者に見られても、正規の電話番号を知られることはありません。このように本来のデータにマスクをかけて保護することから、データマスキングと言われます。
データマスキングは「会員IDの上3桁をマスキングする」「クレジットカード番号の下4桁以外をマスキングする」といったように、設定したルールに基づいてデータを置き換えられます。
しかもマスキングしても、元のデータ構造や形式はそのまま保持しています。元データを隠蔽したダミーデータが生成されるイメージです。見えているのはダミーデータですが、データ構造や形式は失われていないため、統計データとしての利用やテストデータとしての利用が可能です。
例えば、外部のコンサルタントにアンケート結果の集計や分析を依頼する場合、氏名や住所にマスキングをすることで、個人情報を保護することができます。データの利用価値を維持しつつ、情報漏えいのリスクを最小限に抑えることができます。
DXの流れの中で、データの活用ニーズが高まっていますが、データの保護も重要な要件です。企業や組織が情報漏えいのリスクを最小限に抑え、なおかつデータ活用を促進する手段として、データマスキングの注目が高まっています。
(資料DL)データマスキングも可能なiPaaS 活用ユースケース20選ガイドブックを差し上げます。
ダウンロード(無料)
データマスキングとデータ暗号化の違い
データを保護する仕組みとしては、暗号化が広く利用されていますが、暗号化とデータマスキングは何が違うのでしょうか。
暗号化は元となるデータを解読できない状態に変換することです。元のデータに戻すためには、正しい復号化キーを使って復号する必要があります。仮に暗号化データが第三者の手に渡っても、復号化キーがなければ、データは解読できません。データの外部流出や不正利用の防止に非常に有効です。
ただし、暗号化した状態では元のデータ構造や形式は失われるため、暗号化されたままでは利用は不可能。暗号化はデータを守ることに特化した技術と言えるでしょう。ここがデータマスキングとの一番の違いです。
一般的なマスキングデータは不可逆的手法のため、元のデータに復元するアルゴリズムはありません。マスキングされたデータが第三者の手に渡っても、元データに復元することはできません。ただし、元データの一部を変更した場合は、残りの部分から類推される可能性はあります。利用する場合は、類推されるリスクがあることを前提に、変更・隠蔽のルールや適用範囲を工夫することが大切です。
データマスキングとデータ暗号化の違い
マスキングデータの様々な活用法
データの分析・集計
元データを変更・隠蔽しつつ、そのデータ構造や意味を保持しているデータマスキングの特徴を活かせば、機密性やプライバシーを保護しながら、データ活用を促進できます。
例えば、顧客の購買データをもとに分析を行えば、顧客の属性による購買傾向の把握が可能です。詳細なデータがあれば、年齢、性別、居住エリアによる購買傾向などのほか、年収や職業による傾向の違いなども分析できます。アンケート結果を集計し、統計データを作成したり、意見や要望について顧客属性を軸にカテゴライズしたり、といったことも簡単に行えるのです。
個人を特定し得る情報や機微情報をマスキングしても、分析や集計の精度は変わりません。外部に見せたくない情報をマスキングしておけば、これらの作業も安心して外部に委託することができます。
システム開発のテストデータ
データマスキングはシステム開発の現場でもよく利用されています。アプリケーション開発のシステムテストや性能テストでは、網羅的な機能や性能を確認するために、実際にシステムに格納されている本番データ相当の質と量のデータが必要になるからです。
しかし、テスト環境は本番環境とは異なるセキュリティポリシーで運用されており、本番環境ほど厳格なセキュリティで運用されないことがほとんどです。そのため、顧客情報や機密情報が含まれている本番データをそのままテスト環境で使用するのは社内ポリシー上禁止されているケースが多いのです。かといって本番データと同等の質と量のテストデータを一から作成するのは大変な手間です。
マスキング技術を活用すれば、元データが持つユニーク性や分布の多様性、複雑性を保持したテストデータを容易に作成できます。
データマスキングの手法
データマスキングの手法は大きく2つあります。不可逆的手法と可逆的手法です。
不可逆的手法
不可逆的手法は、一度マスキングすると元のデータには復元できません。データを置き換えて、永続的に保護したい場合に有効です。一般的に利用されるデータマスキングは、不可逆的手法です。
可逆的手法
可逆的手法は、特定のキーや情報を使用して元のデータに戻すことが可能です。データを保護しつつ、必要に応じて元のデータを利用することができます。
データマスキングのタイプ
データマスキングにはデータの保護レベルなどによっていくつかのタイプがあります。主なタイプの特徴を解説します。
静的データマスキング
静的データマスキングは、元データをコピーして、そのコピーデータにマスキングを施すものです。元データとは別に、マスキングされたダミーデータが生成されるイメージです。テストデータの作成やデータ分析を委託する目的で、外部にデータを提供する場合などによく利用されます。
動的データマスキング
動的データマスキングは、権限に応じて表示内容を動的に変えることができます。一般従業員には重要情報は表示せず、上長には全情報を表示するといった使い方が可能です。データをマスキングしているだけで、コピーデータは生成されません。データベースやDWHの付加機能として広く利用されています。
決定論的データマスキング
決定論的データマスキングは、同じルールに従って、常に同じマスキング結果を出力するものです。例えば、地名欄の「東京」を「福岡」に変更するルールを設定すれば、データ内の「東京」はすべて「福岡」に置き換わります。マスキングされたデータの一貫性が保たれ、データの関連性や参照性を維持できます。
オンザフライデータマスキング
オンザフライデータマスキングは、データベースへのクエリ時に、即座にデータをコピーしてマスキングするものです。元データは変更されず、マスキングされた結果が表示されます。リアルタイムにマスキングを行いたい場合や、大量データを扱う場合に利用されることが多いです。
(資料DL)データマスキングも可能なiPaaS 活用ユースケース20選ガイドブックを差し上げます。
ダウンロード(無料)
マスキングツールの選定ポイント
データマスキングにはツールの利用が欠かせません。ツールを利用すれば、ルールの設定やマスキング処理、抽出データ以外の不要部分を削除するサブセット化、類似データの生成、匿名性や有用性、照合可能性といったマスキングデータの評価を効率的に行えます。
ツールを選定する場合は以下の5つのポイントが重要になります。
(1)元データの構造を維持
日本語には漢字、ひらがな、カタカナがあり、アルファベットや記号、数字が混在していることもあります。漢字の部分は別の漢字で、ひらがなの部分は別のひらがなで置き換えることで、元データの構造を維持できます。元データの構造を維持したまま、どれだけ多彩なルールを設定できるかが使いやすさを左右します。
(2)データの特性や複雑性の維持
大量のデータにはある種の偏りや分布、ユニークな特徴を持つものなどが混在しています。元データが持つ特性や複雑性を維持している方が、より実データに近い形で活用が可能です。元データの統計情報化やテストデータとして利用する場合に重要なポイントとなります。
(3)参照整合性の維持
参照整合性とは、入力した値が常に同じ値に置き換えられ、マスキングされた出力の一貫性を保証することです。決定論的データマスキングによって実現できます。参照整合性を保持していることで、集計やマッチングがやりやすくなります。
(4)対応するデータソースの種類
ツールによって、対応するデータベースやファイル形式には違いがあります。扱うデータの種類や利用目的を明確にした上で、対応するデータソースの種類を確認することが重要です。
(5)提供形態と料金
ツールの提供形態はパッケージ製品とクラウド型に大別できます。
パッケージは自社でシステムを構築する必要があり、運用・保守も自前で行う必要があります。
クラウド型はツールをサービスとして利用できるため、システム構築や運用の手間・コストを軽減できます。料金は買い切り型、月額固定制などがあります。月額固定でも、一定のデータ量を超えると追加料金が発生するものもあるので、事前の確認が必要です。
代表的なマスキングツール
- Insight Data Masking(株式会社インサイトテクノロジー)
- tasokarena(NTTテクノクロス株式会社)
- フリーテキストマスキング(株式会社アグレックス)
- 個人情報マスキングAIツール(株式会社ユーザーローカル)
- IIJクラウドデータプラットフォームサービス(株式会社インターネットイニシアティブ)
マスキング後のデータ活用も可能なプラットフォームとは
データマスキングはデータの流出や不正利用を防止しつつ、データ活用を進める上で欠かせない技術です。様々なツールが提供されていますが、マスキング後のデータ活用まで考えると、多様なシステムやデータソースの連携性、付加機能の充実度などが重要なポイントになります。
「IIJクラウドデータプラットフォームサービス」はデータ連携・活用のためのプラットフォーム。その機能の1つとしてデータマスキングを提供しています。約90種類の豊富なアダプタで多様なシステムとデータをつなげます。マスキングタイプは静的データマスキングに加え、決定論的データマスキングも利用できます。
漢字、ひらがな、カタカナなどの文字種や文字長を維持したマスキングも可能。データの特性や複雑性、参照整合性も維持します。“使える”データとしてマスキングできるのが強みです。テストデータの作成、集計・分析のためのデータの外部委託、マルチクラウド環境でのセキュアなデータ活用などに最適です。
(関連記事)大量データのマスキングもこんなにカンタン!プライバシーに配慮したデータの高度活用術
更に「IIJクラウドデータプラットフォームサービス」はデータ連携を支えるセキュアなプライベートネットワークも一体的に提供します。また、データフローやワークフローもGUIベースのノーコードで簡単に作成できます。このメリットを活かせば、データの抽出、マスキング、そのデータを連携先システムに登録する一連の処理を自動化できます。煩雑な業務の自動化も実現できるのです。
マスキングだけにとどまらず、その後のデータ活用まで促進できる「IIJクラウドデータプラットフォームサービス」は、DXの取り組みを加速させる有力なソリューションです。
気になることがあればお気軽に
関連資料
